|
Binary - двоичный отбор (логит-преобразование, метод пробитов, экстремальное значение) используется для тех моделей, в которых зависимая переменная Y может принимать два значения.
Ordered - упорядоченный отбор, применяется когда присутствует многообразие скрытых ошибок распределения. Наблюдаемая переменная Y представляется на выходе в виде упорядоченной или ранжированной категории.
Cencored - Цензурированные данные. Используется для оценивания тех моделей в которых зависимая переменная либо цензурирована, либо искажена.
Count - целые, натуральные числовые данные. Применяется, когда Y принимает целые значения, представляющие число событий.
1) Метод наименьших квадратов -
Least
Squares
.
Построим и рассчитаем модель множественной регрессии для всей совокупности независимых факторов (для этого воспользуемся схемой пошагового исследования назад). Чтобы показать уравнение с коэффициентами и уравнение с уже подставленными значениями коэффициентов воспользуемся View/Representations (рис 8).

Рис 8. Уравнение регрессии с помощью МНК
Уравнение регрессии имеет вид:
Y = -0,0001797025244*X1 - 0.02867117878*X2 + 0.0156202727*X3 + 0,05324660079*X4 - 0.0001475263891*X5 + 18.19767146
Уравнение регрессии позволяет понять, как формируется рассматриваемая экономическая переменная потребление сахара:
1) При увеличении валовых сборов сахарной свеклы по Российской Федерации на 1 тыс. тонн потребление сахара уменьшится на 0,00018 кг.
2) При увеличении индекса потребительских цен на 1% потребление сахара уменьшится на 0.029 кг.
) При увеличении посевных площадей на 1 тыс гектаров потребление сахара увеличится на 0.016 кг.
) При увеличении урожайности сахарной свеклы на 1 центнер с одного гектара убранной площади потребление сахара увеличится на 0,053 кг.
) При увеличении среднемесячной номинальной зарплаты на 1 руб потребление сахара уменьшится на 0,00015 кг.
Рассчитываем прогнозное значение потребления сахара на 2012 и 2013 годы. Используя функцию Forecast в объекте Equation, получаем следующие прогнозные значения на 2 года вперёд (рис 9).

Рис 9. Прогнозные значения на 2 года вперед
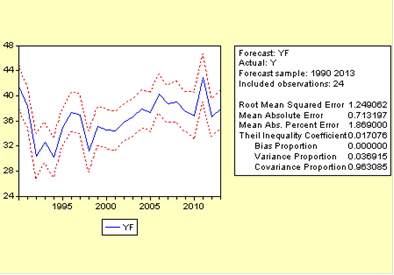
Рис 10. График прогнозных значений.
Как видим, показатели незначительно убывают. Проверка справедливости данных невозможна, так как информации на данный период времени нет.
На рис 11 представлен график уравнения регрессии, построенного с помощью МНК.
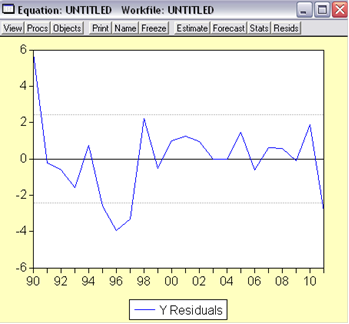
Рис. 11. График уравнения регрессии, построенного с помощью МНК
Оценим статистическую значимость прогнозного уравнения. На рис 12 представлены необходимые показатели.
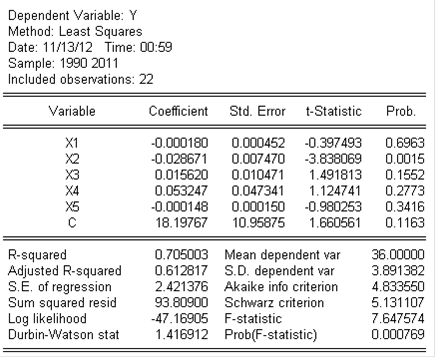
Рис. 12. Показатели уравнения МНК
Рассчитывается коэффициент детерминации - показатель, отражающий в какой мере функция регрессии определяется экзогенными переменными. Чем ближе коэффициент детерминации к единице, тем лучше регрессия аппроксимирует эмпирические данные и ею можно воспользоваться для прогноза значений результативного признака.
Мерой качества уравнения регрессии, характеристикой прогностической силы анализируемой регрессионной модели является коэффициент детерминации(R-squared). Он показывает, какая часть вариации зависимой переменной обусловлена вариацией объясняющей переменной. Чем ближе коэффициент детерминации к единице, тем лучше регрессия аппроксимирует эмпирические данные.
Коэффициент детерминации R2=0,7050003>0,7 говорит о том, что доля влияния независимых переменных на зависимую значительна (71%).
Адекватность регрессии опытным данным можно проверить с помощью критерия Фишера F-statistic и вероятности Prob (F-statistic). Выдвигается нулевая гипотеза H0 о статистической незначимости линейного уравнения регрессии в целом и отсутствии связи между зависимой и независимыми переменными (bi = 0 и ryxi = 0). Если Prob (F-statistic) > a=0,05, то H0 принимаем.
Перейти на страницу: 1 2 3 4 5 |